The task of instance segmentation is essential in computer vision, especially in the field of autonomous driving and robotics. It involves identifying and separating individual objects within an image, and assigning a unique label to each object pixel.
In recent years, deep learning has revolutionised instance segmentation, with the introduction of various models, such as Mask R-CNN, YOLO, and CenterNet. However, these models have their limitations, such as high computational cost and low accuracy on small objects.
The Mask2Former is a new model that aims to overcome these limitations, and in this article, we will break down the benefits of the Mask2Former Train on Instance Segmentation Task.
What is Mask2Former?
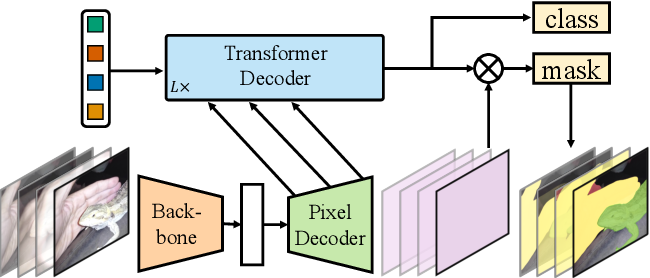
Mask2Former is a novel model that combines two popular architectures in deep learning, the transformer, and the mask head. The transformer is known for its ability to capture long-range dependencies in the input sequence, while the mask head is responsible for generating the segmentation masks. Mask2Former leverages the strengths of both architectures to achieve high accuracy on instance segmentation tasks, while reducing the computational cost.
How does Mask2Former work?
Mask2Former works by first generating a set of features maps from the input image using a backbone network, such as ResNet. These feature maps are then fed into a transformer encoder-decoder architecture, which generates a set of context-aware feature maps. The context-aware feature maps are then passed to the mask head, which generates the final segmentation masks.
How is Mask2Former different from other models?
Mask2Former differs from other models in several ways. Firstly, it leverages the transformer architecture, which has not been used extensively in instance segmentation tasks. Secondly, it uses a novel mask head that is optimised for small object detection, which is a common problem in instance segmentation. Finally, it achieves state-of-the-art performance on various benchmark datasets, while reducing the computational cost compared to other models.
Benefits of Mask2Former Train on Instance Segmentation Task
Improved Accuracy
One of the main benefits of Mask2Former Train on Instance Segmentation Task is the improved accuracy. The transformer architecture in Mask Former allows the model to capture long-range dependencies in the input sequence, which is essential for accurately identifying and segmenting objects in an image. The unique mask head of Mask2Former is optimized for small object detection, a common issue in instance segmentation.
Reduced Computational Cost
Another benefit of Mask2Former Train on Instance Segmentation Task is the reduced computational cost. Mask2Former achieves state-of-the-art performance on various benchmark datasets, while reducing the computational cost compared to other models. By utilizing the transformer and mask head architectures, the number of computations needed for segmentation masks can be reduced.
Faster Training Time
Mask2Former Train on Instance Segmentation Task also has a faster training time compared to other models. This is due to the reduced computational cost, which allows for faster training on large datasets. Additionally, the transformer architecture in Mask Former allows for parallel processing, which further reduces the training time.
Higher Generalisation
Mask2Former Train on Instance Segmentation Task also has higher generalisation compared to other models. This is because the transformer architecture in Mask Former allows the model to capture long-range dependencies in the input sequence, which makes it more robust to variations in the input. Additionally, the novel mask head in Mask2Former is optimised for small object detection, which is a common problem in real-world applications.
Also read : Create Invitations Using Party Invitation Templates in Minutes
FAQs:
Q: What is instance segmentation?
A: Instance segmentation is the task of identifying and separating individual objects within an image, and assigning a unique label to each object pixel.
Q: What are the limitations of existing instance segmentation models?
A: Existing instance segmentation models have limitations such as high computational cost and low accuracy on small objects.
Q: How does Mask2Former work?
A: Mask2Former works by combining the transformer and mask head architectures to generate context-aware feature maps and segmentation masks, respectively.
Q: What are the benefits of ?
A: The benefits include improved accuracy, reduced computational cost, faster training time, and higher generalisation.
Q: What is the future of instance segmentation models?
A: With the evolution of computer vision, there is an anticipation for increased research to enhance the accuracy and efficiency of instance segmentation models.
Conclusion:
Mask2Former Train on Instance Segmentation Task is a novel model that combines the transformer and mask head architectures to achieve state-of-the-art performance on various benchmark datasets, while reducing the computational cost and training time.
The model also has higher generalisation compared to other models, which makes it more suitable for real-world applications. As the field of computer vision continues to evolve, it is expected that more research will be done to improve the accuracy and efficiency of instance segmentation models, and Mask2Former is a promising step in that direction.



